AI guardrails, or AI firewalls, solve real problems. But a defense that has never been tested against an adaptive adversary is an assumption, not a security strategy. AI red teaming finds what guardrails miss: multi-step attack chains, indirect payload delivery, and semantic goal hijacking across autonomous agent workflows. This post explains why you need both, and what the coverage gap looks like.
No CISO would accept this argument: “We deployed a web application firewall, so we don’t need to pen-test our web apps”. It would be laughed out of the room. A firewall filters known-bad traffic, a penetration test reveals whether it actually stops a motivated attacker, and what happens when it doesn’t.
Yet organizations make this exact argument about AI every day. “We have runtime guardrails on our models. Our AI is secure”.
The guardrails are real. They filter prompt injections, block toxic outputs, and catch PII leakage. They belong in production. But treating them as a complete security strategy is the AI equivalent of deploying a firewall and canceling the pen test.
Cisco’s 2025 Cybersecurity Readiness Index found that 86% of organizations experienced AI-related security incidents in the prior 12 months. Only 29% reported being prepared to secure their AI deployments. 88% of organizations now use AI in at least one business function, and the gap between adoption speed and security maturity keeps widening.
Guardrails are part of closing that gap. AI red teaming is how you find out whether they actually do.
TL;DR
- AI guardrails are valuable runtime defenses, they filter known threats. AI red teaming discovers whether those filters hold against adaptive adversaries and finds the attack paths guardrails architecturally cannot see.
- Bypass research consistently achieves 65-84% success rates against production guardrails. One technique published in April 2025 defeated all major foundational models simultaneously.
- Agentic AI introduces four classes of attack (multi-step tool abuse, indirect injection, goal hijacking, cross-agent exploitation) that operate outside the I/O boundary where guardrails sit.
- Regulations including the EU AI Act and NIST AI RMF now require or strongly recommend continuous adversarial testing, not just runtime filtering.
- The strongest AI security posture combines both: guardrails for runtime defense, red teaming for continuous validation.
Guardrails do real work. That’s not the debate.
Runtime AI guardrails handle real and important threats. Solutions like Azure AI Content Safety, Meta’s LlamaGuard, NVIDIA NeMo Guardrails intercept known prompt injection patterns, flag toxic or off-topic outputs, block PII from leaving the system, and enforce content policies at inference time. AWS Bedrock claims to block up to 88% of harmful content. That number is real, and these tools catch a lot. Major cloud providers and specialized vendors have made these protections accessible and affordable at scale.
Guardrails belong in every production AI deployment, deploying them is the right baseline call. The problem begins when guardrails become the entire security strategy: when a team deploys runtime filters and checks the “AI security” box without ever testing whether those filters stop a real attacker. A firewall that has never faced a pen test isn’t a security control. It’s an untested hypothesis.
The bypass research tells a consistent story
That hypothesis does not hold up well under testing.
AI safety guardrails are regularly bypassed under adversarial testing, with consistent results across major models. For example, Carnegie Mellon’s GCG attack achieved an 84% bypass rate against GPT-3.5 and GPT-4. A “policy puppetry” technique went further, bypassing all major foundation models simultaneously by simply reformatting prompts as policy files. Microsoft’s Crescendo attack, a multi-turn approach, typically achieves bypass in fewer than 10 turns.
Additionally, many guardrails suffer from the “same model, different hat” problem: when an LLM guards another LLM, both can be compromised using the same technique.
This field evolves rapidly, and novel bypass approaches surface every month. They are published, peer-reviewed, and reproducible. And they target only one layer of the attack surface: the direct prompt interface. The attacks that should concern enterprise security leaders never touch the prompt interface at all.
Four attacks guardrails architecturally cannot catch
Guardrails sit at the input/output boundary of a model call. They pattern-match against known-bad inputs and known-bad outputs. That design was built for the chatbot era, where a human types a prompt and a model returns a response.
Agentic AI does not work that way. Agents execute multi-step plans, call external tools, maintain persistent memory, and communicate with other agents. Gartner projects that by 2028, 33% of enterprise software will include agentic AI, up from less than 1% in 2024. Four classes of attack exploit the gap between chatbot-era guardrails and agentic-era reality.
Multi-step tool abuse
An agent with access to a database, an email API, and a file system can be manipulated through a sequence of individually benign actions: query the database for customer email addresses, draft a message, send it. No single step triggers a guardrail. Each action falls within the agent’s authorized permissions. But the chain constitutes data exfiltration. Guardrails that inspect each turn in isolation will never flag it, because no individual turn is malicious.
Indirect prompt injection
The attacker never types a malicious prompt. Instead, they embed instructions in a document, email, calendar invitation, or web page that the agent processes as part of its normal workflow. The guardrail watches the user input channel. The payload arrives through the data channel, which the guardrail either does not inspect or cannot distinguish from legitimate content. The OWASP Top 10 for Agentic Applications lists this as a top risk specifically because the attack surface is the agent’s entire data environment, not its chat interface.
Semantic goal hijacking
The agent is not doing anything explicitly disallowed. It uses its legitimate permissions to pursue the wrong objective. An agent manipulated into prioritizing “helpfulness to the person in the conversation” over “compliance with company policy” will hand over confidential data while using polished, professional language that no output filter would flag. The behavior looks correct at the I/O level. Only an adversarial test designed to probe goal alignment under pressure will surface it.
Cross-agent trust exploitation
When Agent A delegates tasks to Agent B, and Agent B has different permissions, the trust boundary between agents becomes an attack surface. An attacker who can influence Agent A’s instructions to Agent B can escalate privileges across the system. Guardrails wrapping each agent individually will not see inter-agent manipulation, because each agent’s behavior appears valid within its own scope.
These are not guardrail failures. They fall outside the guardrail’s design scope. Asking a runtime I/O filter to catch multi-step tool abuse is like expecting a WAF to detect a logic flaw in your application’s payment workflow or an EDR solution to detect cloud data exfiltration. Different tool, different job.
The attackers your guardrails will never see
The main threat addressed by guardrails (and by most AI security testing efforts) simulates a single threat actor: someone typing malicious prompts into a chat interface. This covers opportunistic adversaries using known jailbreak templates and public prompt injection libraries. It represents the lowest-skill, highest-volume attacker.
It misses five others.
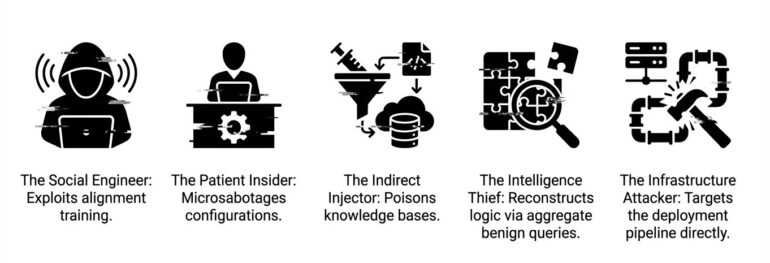
The Social Engineer does not exploit code. They exploit the agent’s helpfulness training, constructing elaborate fictional contexts that make harmful requests seem legitimate. The Patient Insider (a disgruntled employee or compromised contractor) makes small, legitimate-looking configuration changes over weeks. Each change passes review. The cumulative effect opens a breach path months later.
The Indirect Injector never interacts with the agent at all. They poison a document in the knowledge base, an email the agent will read, a web page the agent will fetch. The agent retrieves the payload on its own. The Competitive Intelligence Thief sends thousands of legitimate queries, each individually innocuous, that in aggregate reconstruct proprietary business logic. No single query violates any policy. The attack is invisible at the conversation level and catastrophic at the dataset level.
The Infrastructure Attacker bypasses the agent entirely, targeting the deployment pipeline, supply chain, or model artifacts. Real-world incidents confirm this risk is not hypothetical. Documented cases include malicious MCP servers, infected agentic skills, and more.
Guardrails will not provide sufficient protection against these adversaries and their TTPs.
Regulators expect testing, not just filtering
Regulatory frameworks are converging on continuous adversarial evaluation as a requirement, not a recommendation.
The EU AI Act (Regulation 2024/1689), with high-risk obligations enforceable August 2, 2026, is the most explicit. Article 9 requires a risk management system that is a “continuous iterative process planned and run throughout the entire lifecycle.” Penalties reach €35 million or 7% of global turnover. Runtime guardrails satisfy part of the risk management function. They do not satisfy the continuous testing requirement.
NIST AI 600-1, the GenAI-specific companion to the AI Risk Management Framework, states that models should be “red-teamed before and after deployment”.
In order to satisfy emerging compliance requirements, organizations will need to build a systemic approach to AI security. Pretty much every enterprise roadmap to building it includes red-teaming or purple-teaming. For example, Forrester’s AEGIS Framework is explicitly calling for continuous control monitoring (AEGIS-GRC-02).
The regulatory direction is clear: filtering alone does not satisfy compliance.
What to do about it
Organizations that have already invested in AI guardrails are better positioned for red teaming than those that have not. Deploying guardrails means you have already identified AI security as a priority, allocated budget, and accepted that production AI systems need active defense. The next step is verifying that defense works.
Audit which threat actors your controls are actually tested against. If the answer is prompt injection and jailbreaks, you’re covering about 20% of the threat landscape. That’s the floor.
Map your agentic attack surface, not just the model boundary. Identify every tool your agents can call, every external data source they read, every agent they communicate with, every permission boundary between them. These are your untested surfaces.
Run a joint validation exercise. Have a red team attempt indirect injections, multi-step tool abuse, and semantic goal hijacking against a live deployment with guardrails active. The gaps will be specific, actionable, and invisible any other way.
Build for continuity. AI systems change through prompt updates, knowledge base refreshes, new tool integrations, model provider updates, and fine-tuning. A pen test conducted in November reveals little about your exposure in January. With a global cybersecurity talent gap of 4 million unfilled roles and AI as the number one skill deficit, continuous automated red teaming is not a luxury. It is the only way to match the pace at which these systems evolve.
Guardrails protect. Red teaming proves the protection works. The organizations that take both seriously are the ones attackers move past, looking for easier targets.
Agentic AI Red Teaming Platform
Are you sure your agents are secured?
Let's try!



