This digest reviews four pivotal research papers that shed light on diverse dimensions of AI, from exploring vulnerabilities in Natural Language Inference (NLI) models and Generative AI to investigating adversarial attacks and defenses on 3D Point Cloud Classification, and unveiling the potential misuse of multi-modal LLMs.
Each study underlines the overarching theme of model security robustness and privacy, pivotal aspects in our digital age.
Subscribe for the latest AI Security news: Jailbreaks, Attacks, CISO guides, and more
NatLogAttack: A Framework for Attacking Natural Language Inference Models with Natural Logic
The paper investigates how Natural Language Inference (NLI) models can be manipulated. The researchers designed a framework called NatLogAttack which uses natural logic for adversarial attacks. Their tests found that NLI models were susceptible to these attacks, with significant drops in their performance. This study highlights the vulnerability of NLI models, calling for improved security measures and robust model design.
From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy
The research focuses on the implications of generative AI in cybersecurity. The authors studied the potential for misuse of advanced models like ChatGPT, revealing that they can indeed be weaponized for nefarious purposes. This work underscores the pressing need for comprehensive security measures and privacy safeguards in generative AI models.
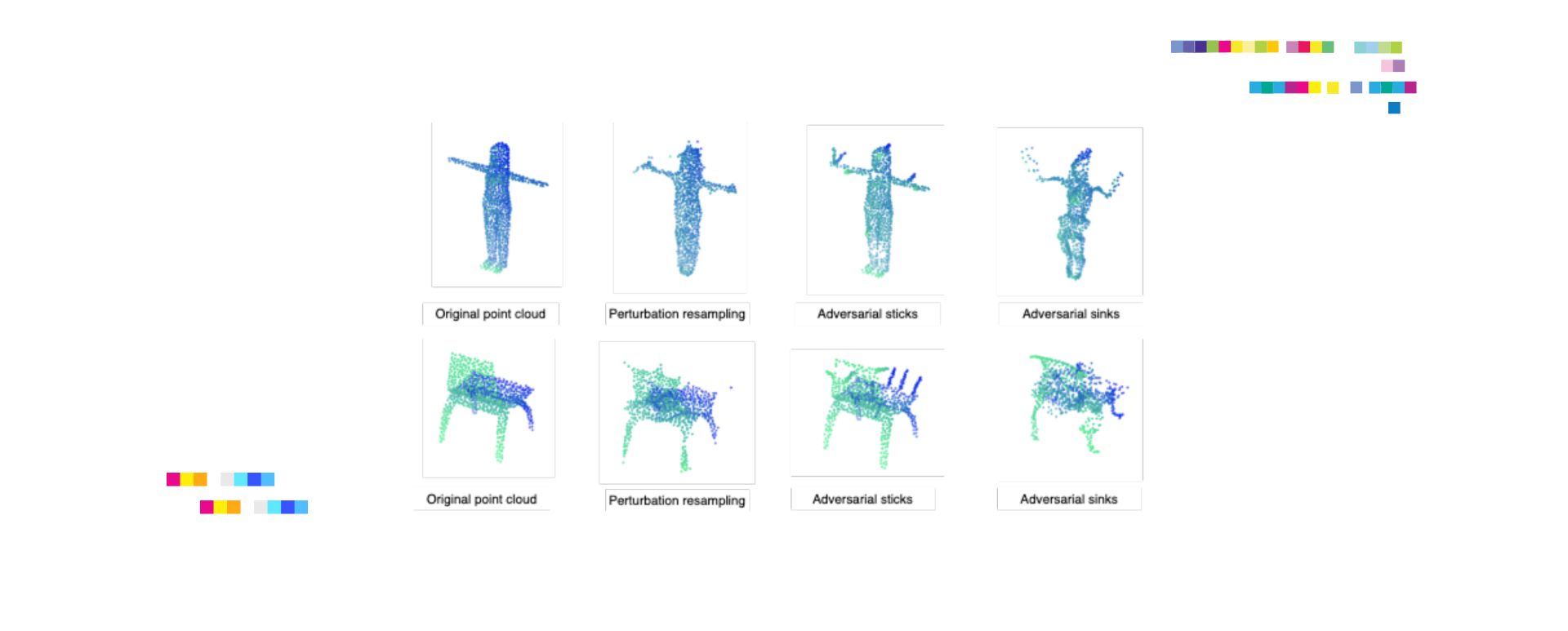
Adversarial Attacks and Defenses on 3D Point Cloud Classification: A Survey
The study delves into the vulnerability of deep learning algorithms on 3D point clouds. The researchers conducted a comprehensive survey of current adversarial attack and defense techniques in the realm of 3D point cloud classification. They observed that while deep learning has shown great potential in handling 3D point cloud tasks, they are prone to adversarial attacks. The research provides a crucial overview of this field and encourages future study into effective defense strategies.
(Ab)using Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs
The paper examines how multi-modal LLMs can be exploited for indirect instruction injection. The researchers exploited vulnerabilities in multi-modal LLMs using images and sounds, demonstrating successful indirect instruction injections. This research opens the door for necessary advancements in the security protocols and safety measures for multi-modal LLMs.
All these four papers, despite their diverse focus areas, converge on a central theme – the vulnerabilities and potential misuse of AI models. This shared focus on the theme of model robustness and privacy highlights the ongoing challenges in AI research and underscores the critical need for further studies that can help in building secure, reliable, and robust AI models.
Subscribe now and be the first to discover the latest GPT-4 Jailbreaks, serious AI vulnerabilities, and attacks. Stay ahead!