The Adversa team makes for you a weekly selection of the best research in the field of artificial intelligence security
Predicting the trajectory of a vehicle is extremely important for self-driving cars. Modern methods are impressive, but they have no off-road predictions, they have a number of shortcomings. Researchers Mohammadhossein Bahari, Saeed Saadatnejad, Ahmad Rahimi, Mohammad Shaverdikondori, and Mohammad Shahidzadeh present a new method that automatically creates realistic scenes that make modern models go off-road.
They presented the problem through the lens of an adversarial scene and decided to promote a simple yet effective generative model based on atomic scene generation along with physical constraints. Experiments show that over 60% of existing scenes from current tests can be modified so that off-road prediction methods do not work.
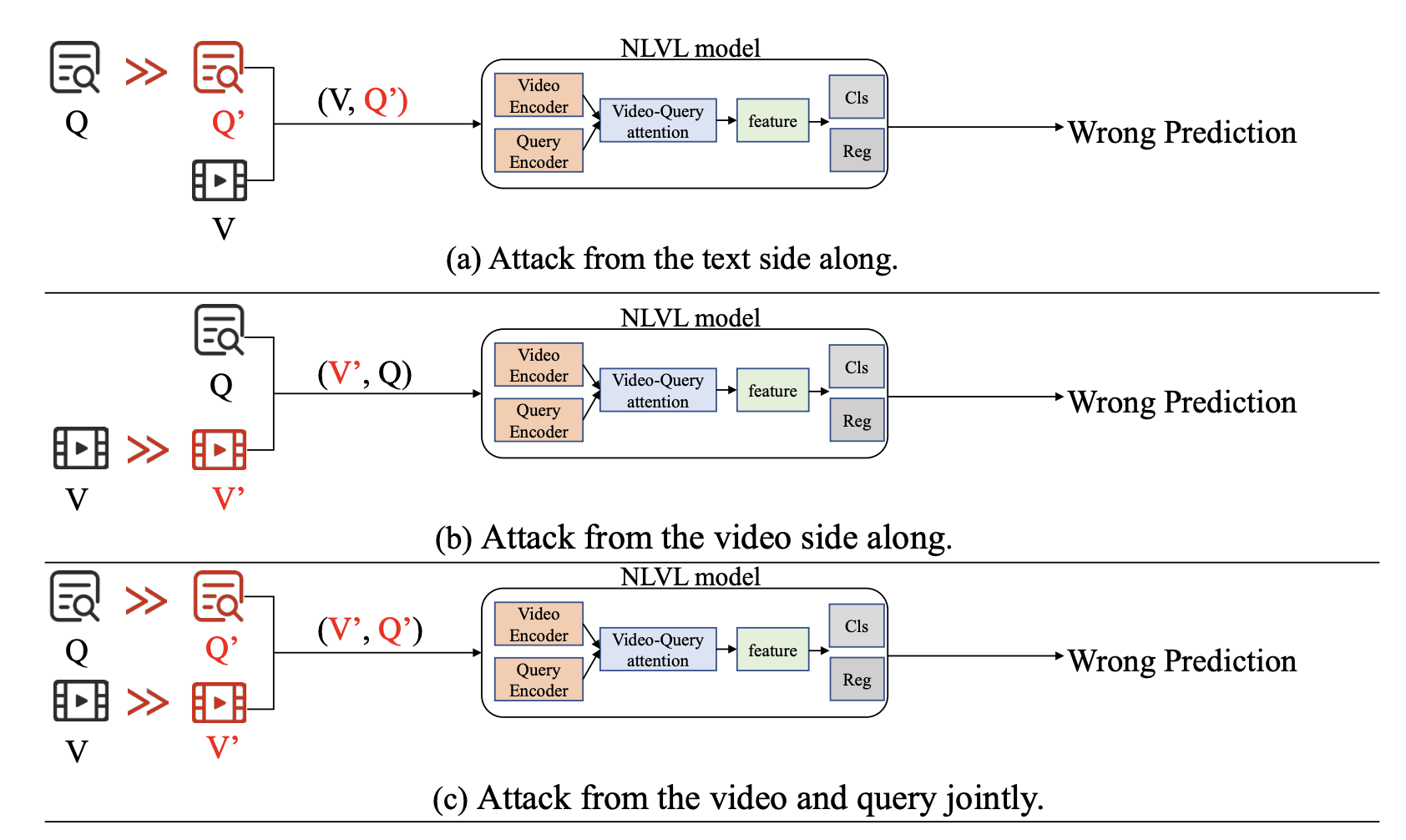
Natural Language Video Localization (NLVL) is an important challenge in the field of visual language understanding. This problem requires a deep understanding of computer vision and the natural language side, as well as the interaction between both sides. The adversarial vulnerability has been recognized as a critical security issue for deep neural network models, and there is a large body of research on video and language problems at the moment. In this article, researchers Wenbo Gou, Wen Shi, Jian Lou, Lijie Huang, Pan Zhou, and Ruixuan Li have gone further by focusing on the adversarial robustness of NLVL models by examining three dimensions of vulnerabilities from both attack and defense perspectives.
The paper proposes a new adversarial attack paradigm called an adversarial attack based on synonymous sentences on NLVL (SNEAK). The new method reflects the cross-modal interaction between vision and language.
In federated learning, data does not leave personal devices during co-training of a machine learning model. The devices then exchange gradients with the center side, and FL is presented as preserving confidentiality. However, such models have a number of serious vulnerabilities. In this paper, researchers Franziska Boenisch, Adam Dziedzic, Roei Schuster, Ali Shahin Shamsabadi, Ilia Shumailov, and Nicolas Papernot.
Experts imagine an active and dishonest attacker acting as a central party – he can change the weights of the overall model before users calculate the gradients of the model.
The modified weights are called “trap weights,” and an attacker can recover user data at almost zero cost, without requiring complex optimization tasks. To do this, internal data leakage from the model’s gradients is used and amplifies this effect by maliciously changing the weights of the overall model. These features allow us to scale our attack on models trained with large data.