The Adversa team makes for you a weekly selection of the best research in the field of artificial intelligence security
Machine learning is widely used in a variety of mission-critical applications, from autonomous driving to authentication systems, but this growth in popularity has met with attacks on these systems. One such attack is a temporary training attack. In this attack, the hacker performs his attack before or during training of the machine learning model. In this paper, researchers Ahmed Salem, Michael Backes, and Yang Zhang propose a new time training attack against computer vision-based machine learning models – model hijacking. These attacks are carried out in the same way as existing data poisoning attacks.
An attacker seeks to hijack the target model in order to perform a different task from the original without the knowledge of the model owner, and hijacking the model can pose accountability and security risks as the owner of the stolen model could be accused of offering illegal or unethical services.
However, one of the conditions for such an attack is to be hidden, and the data samples used to intercept the target model must look similar to the original training dataset of the model. To do this, the researchers presented two different intercept attack models – Chameleon and Adverse Chameleon. They are based on a new encoder-decoder style machine learning model, Camouflager. The researchers estimate that both eavesdropping attack models achieve high attack success rates with a slight decrease in the usefulness of the model.
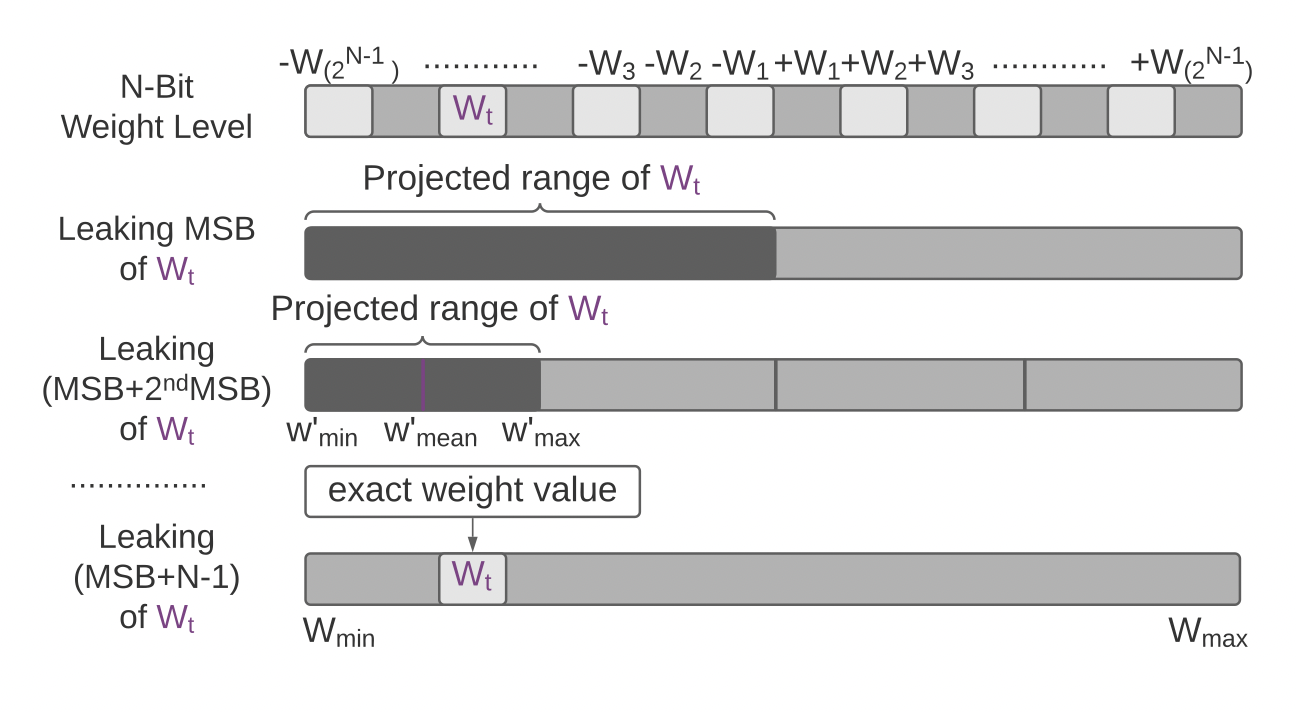
DNNs are widely used in a variety of safety-sensitive applications. The need for resource-intensive training and the use of valuable data for training in a specific subject area has led the models to become the intellectual property (IP) of the owners. At the same time, one of the main threats in this case is model extraction attacks, in which a hacker targets confidential information in models. Hardware side-channel attacks can reveal internal knowledge of DNN models.
However, existing attacks cannot extract detailed model parameters, and in this paper, researchers Adnan Siraj Rakin, Md Hafizul Islam Chowdhuryy, Fan Yao, and Deliang Fan propose for the first time an extended DeepSteal model extraction attack structure. This attack effectively steals DNN weights using a side-channel memory attack. The proposed DeepSteal includes a new method for extracting information about weight bits, called HammerLeak, by applying the Rowhammer-based hardware failure method as the information leakage vector. The method employs several new system-level techniques designed for DNN applications to enable rapid and effective weight stealing. In addition, the researchers present a new algorithm for training a replacement model with a penalty for the average clustering weight. It makes good use of partial bit information leakage and generates a replacement prototype for the target victim model. The algorithm has been shown to be highly effective in a number of studies.
Deep neural networks ezpdbvs to malicious changes in natural input data that are invisible to humans, and adversarial learning is currently the most effective defense mechanism. It creates adversarial examples during training by repeatedly maximizing losses. After that, the model is trained in order to minimize possible losses. However, this min-max optimization requires a large amount of data, a larger model, and additional computational resources, which degrades the standard generalization characteristics of the model.
In this study, experts Muhammad Awais, Fengwei Zhou, Chuanlong Xie, Jiawei Li, Sung-Ho Bae, and Zhenguo Li asked whether it is possible to achieve reliability in a more efficient way in terms of knowledge transfer. The paper theoretically shows the possibility of transferring resilience from the competitive teacher model to the student model by increasing confusion. Thereafter, a new method of transferring reliability is proposed, called Mixup-Based Activated Channel Maps (MixACM) Transfer. This method transfers reliability from a trusted teacher to a student by matching activated channel maps, created without costly adversary intervention. Repeated experiments with multiple datasets and different training scenarios demonstrate that our method can have a significant impact on reliability as well as improve generalization on natural images.