The Adversa team makes for you a weekly selection of the best research in the field of artificial intelligence security
Federated learning (FL) has recently gained particular attention as a machine learning technique due to its ability to effectively protect customer confidential information. Unfortunately, the FL models are still significantly vulnerable to many attacks that compromise data privacy and security. The existing adversarial models for untargeted model poisoning attacks are not sufficiently stealthy and stable at the same time.
Researchers Md Tamjid Hossain, Shafkat Islam, Shahriar Badsha, and Haoting Shen decided to explore adversarial learning in the FL environment. The object of their research was a covert and persistent poisoning attack on a model that could be carried out using differential noise; more specifically, they were working on a new DeSMP model poisoning attack using DP for FL models. Repeated testing using two popular datasets reflect the effectiveness of the proposed DeSMP attack.
Recommender systems have achieved good results and are widely adopted. Often, such systems are trained on highly sensitive user data, so a potential data leak can have serious consequences.
Researchers Minxing Zhang, Zhaochun Ren, Zihan Wang, Pengjie Ren, Zhumin Chen, Pengfei Hu, and Yang Zhang attempted to quantify the privacy leak of recommendation systems in terms of membership. The attack is unique in that it is carried out at the user level and not at the data sampling level. In addition, an attacker can only observe ordered recommended items from the recommender system. A novel method represents users from relevant items. Also, a shadow recommender can derive the labeled training data for training the attack model. Based on extensive experimental results, attack framework provides high performance.
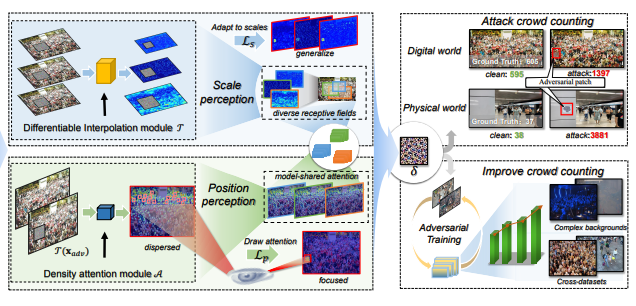
Crowd counting, which is widespread at the moment and is used in safety-critical scenes, has proven to be overly vulnerable to adversarial attacks. While adversarial examples help to better understand the robustness of the model, current adversarial methods are not very transferable across different black box models.
In addition, portability is known to be positively correlated with model invariant characteristics. Therefore, researchers Shunchang Liu, Jiakai Wang, Aishan Liu, Yingwei Li, Yijie Gao, Xianglong Liu, and Dacheng Tao propose a Perceptual Adversarial Patch (PAP) framework to study shared perceptual characteristics between models using model scale perception and position perception. In addition, it has been found that adversarial patches proposed by researchers can also be used to improve the performance of conventional models to alleviate several problems, including cross datasets and complex backgrounds. The effectiveness of the proposed PAP has been demonstrated in both digital and physical world scenarios.