The Adversa team makes for you a weekly selection of the best research in the field of artificial intelligence security
Generative Network of Opponents (GAN) are highly developed and are often used to create highly realistic photographs that can be used, for example, to create fake images on social networks.
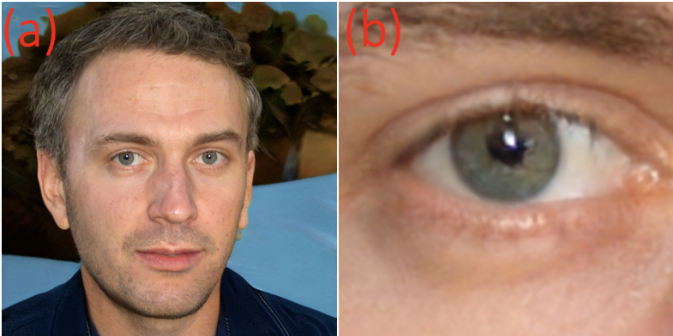
Generative Network of Opponents (GAN) are highly developed and are often used to create highly realistic photographs that can be used, for example, to create fake images on social networks. In this paper, researchers Hui Guo, Shu Hu, Xin Wang, Ming-Ching Chang, and Siwei Lyu demonstrate that GAN-generated faces can be easily identified by irregular pupil shapes, moreover, this phenomenon is common even in high-quality GAN-generated faces. The paper also describes an automatic method of the pupils extraction from two eyes and analysis of their shapes for detecting the GAN-generated faces.
Deep neural networks have reached strong development and are used everywhere. Facial recognition systems, like other DNNs, have nevertheless demonstrated their vulnerability to various types of adversarial attacks, and since facial recognition technologies are often used to protect confidential information, hostile attacks on the bottom can pose a real threat.
Researchers Chang-Sheng Lin, Chia-Yi Hsu, Pin-Yu Chen and Chia-Mu Yu present a physical adversarial attack using full face makeup where the cycle-adversarial generative network (cycle-GAN) and a victimized classifier are combined. we propose a physical adversarial attack with the use of full-face makeup. The presence of makeup on the human face is a reasonable possibility, which possibly increases the imperceptibility of attacks. In our attack framework, we combine the cycle-adversarial generative network (cycle-GAN) and a victimized classifier. The Cycle-GAN can generate adversarial makeup, while the architecture of the targeted classifier is VGG 16. According to the results of the studies, the attack can effectively overcome manual errors in makeup application, including color and position-related ones.
In the recent work, researchers Guanxiong Liu, Issa Khalil, Abdallah Khreishah and NhatHai Phan have demonstrated the ways of joint exploitation of adversarial perturbation and model poisoning vulnerabilities launching a new stealthy attack, called AdvTrojan.
The attack can be activated when an adversarial perturbation is injected into the input examples during inference, and when a Trojan backdoor is implanted during the training process. The attack can be performed by poisoning the training data (like in conventional Trojan backdoor attacks). According to research results, an attack can bypass existing defenses with a success rate close to 100%.