
insert_link
share
close
Top Agentic AI security resources — June 2026
June 2026’s agentic AI security roundup: coding agent RCEs, Microsoft Semantic Kernel flaws, a Copilot backdoor, and the newest agent defenses.

The AI Agent Risk Quadrant (AIRQ) Report scores 100 popular agents across 10 classes on how exposed they are, how much damage a compromise causes, and what defenses hold. AIRQ Framework is a tool to run the same assessment on the agents in your own stack.
Your favorite corporate platforms all became agents. The chat tool now browses, the coding assistant now runs commands, the workflow app now reaches into your SaaS and acts on your behalf. Each of those upgrades shipped as a feature. None of them shipped as a security decision you got to make. Adversa AI together with industry contributors and reviewers built the AIRQ to answer that: which agents in your stack are safe, and which aren’t.
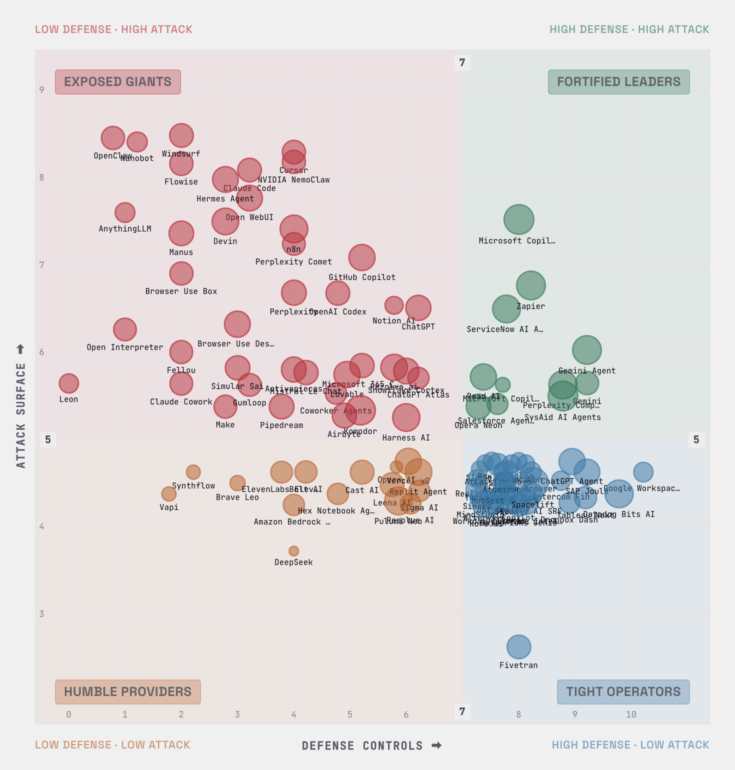
AIRQ Framework measures every agent on three independent axes.
Attack surface asks how exposed the agent is, across the input and execution paths an attacker could use to steer it. Blast radius asks how bad it gets if the agent is compromised, from reading data it should not to taking actions it cannot take back. Defensive controls score asks what is in place to stop that, from constrained identity to execution isolation to approval gates on irreversible actions.
Plotted together, those axes form the quadrant the framework is named for: high or low surface against high or low defense. An agent with broad reach and thin defense is an Exposed Giant. Broad reach with matching defense is a Fortified Leader. Narrow and well-guarded is a Tight Operator. Narrow and lightly guarded is a Humble Provider. The placement is a starting point for a risk conversation, not a verdict, and you can apply the same axes to your own internal builds.
The part most scoring leaves out is the fourth layer: how strong is the evidence behind each claim. A control backed by source code or a third-party AppSec assessment counts for more than one that only lives in a vendor datasheet. That distinction matters because, in the current cohort, 83% of claimed defenses are not publicly verifiable. AIRQ scores the claim and the proof separately, so a confident marketing page cannot pass for a tested control.
AIRQ is built to be operated. Three uses cover most of what an enterprise needs from it.
Vet your stack. Compare and rank the 100 scored agents across 10 classes, then drill into a specific agent’s risk profile and the attack and defense detail behind its score. If your developers live in Claude Code, you can see where it lands against other coding agents instead of guessing. Comparison only means something within a class and quadrant, so the explorer keeps you comparing agents that are structurally alike rather than ranking a coding agent against a voice agent.
Grill your vendors. Because the methodology mirrors what a security team can test, the questions it asks are the ones you can put straight to a vendor. The ten attack surface factors, six blast radius factors, and five defense components double as a procurement questionnaire. If a vendor cannot answer them with evidence, that absence is your answer.
Track your drift. The agent you approved yesterday can change overnight. A platform update widens its retrieval scope, a new connector expands its reach, a default flips. A Gemini Workspace rollout or a new security capability in something like OpenClaw can move an agent’s profile to a better or worse position without anyone filing a ticket. Reassessing on the same axes shows where the agent moved and where you now need more defense. Score it twice while you are at it, once vendor-as-shipped and once customer-as-configured, because those builds routinely land points apart.
The AIRQ Framework methodology ages better than any individual score. AIRQ combines NIST, OWASP, MITRE, CoSAI, and CSA guidance into one transparent scoring system, and every weight and rule is published and auditable on the methodology page. The methodology is open source and free to use, and the report itself is free and open. It is vendor-neutral, with contributors and reviewers from OWASP, CoSAI, the Cloud Security Alliance, and others.
That makes it a practical instrument for AI agent threat modeling. The same factor lists are checklists for red-team scoping, architecture review, and control gap analysis. Each AIRQ factor maps to an established standard, which turns broad guidance into scored, auditable lists you can act on.
One report finding makes the initial triage easier: whether an agent executes tools, and whether that execution is sandboxed, explains 76% of blast radius. Ask those two questions before you open anyone’s deck.
Running the full methodology across the cohort produced a state-of-the-field report, and the picture is grim. Only 11% of agents are both capable and well-defended. The largest group, 40%, pairs broad capability with thin defense. Capability and defense pull in opposite directions across most of the market: the agents with the most power tend to carry the least protection.
The lethal trifecta is nearly universal. 98% of the cohort combines private data access, exposure to untrusted inputs, and the ability to communicate externally. When those three sit together, one hostile document can turn the agent against its operator, and the controls that would interrupt that chain are the ones most often missing. Eight of ten agent classes show 100% trifecta exposure.
Treat these numbers as a point-in-time reading of enterprise AI agent risk, not a permanent scoreboard. Vendors ship defenses, attackers find new paths, and configurations change. The value is in watching the trend across editions, which is the better signal for how seriously a vendor treats security over time.
AIRQ works on three horizons. Right now, use the explorer in the AIRQ Report to vet the agents already in your stack and rank the alternatives. This quarter, put the AIRQ Framework methodology’s questions to your vendors and require evidence. Going forward, bookmark the report and reassess as platforms shift under you, because a clean record today is unexamined, not safe.
When you are ready to act on what you find, the report carries a prioritized action list for teams building, buying, or governing agentic systems. It is grouped by domain (procurement, governance, inventory, and monitoring) and ordered within each group by expected risk reduction against implementation effort, so the first item in each list is the cheapest large win.
It costs nothing to start. Compare your agents, pressure-test your vendors, and share the link: airq.adversa.ai.
June 2026’s agentic AI security roundup: coding agent RCEs, Microsoft Semantic Kernel flaws, a Copilot backdoor, and the newest agent defenses.
