Recently, Adversa’s AI Red Team, a research division at Adversa AI, in collaboration with CUJO AI, Microsoft, and Robust Intelligence organized the annual Machine Learning Security Evasion Competition (MLSEC 2022).
The contest announced at DEFCON AI Village has united practitioners in AI and cybersecurity fields in finding AI vulnerabilities and sharing successful AI attack methods.
Subscribe for the latest LLM Security news: Jailbreaks, Attacks, CISO guides, VC Reviews and more
This year, hackers attacked AI facial recognition and AI phishing detection systems. Contestants tried to fool AI models in different ways and demonstrate the vulnerabilities of AI algorithms.
Both AI victim systems were proven to be susceptible to evasion attacks. This serves as a reminder that most AI algorithms are insecure by design, and it takes extra effort to protect them from adversarial attacks.
AI Hacking Competition for Phishing Detection
The attack challenge against phishing detectors was prepared by CUJO AI led by Zoltan Balazs. The goal of attacks was to modify phishing HTML pages in a way that the page would be rendered exactly the same, but it would no longer be detected as malicious.
Last year, they only trained the phishing detection ML models on static HTML files. From the beginning, it was clear that encoding the HTML and decoding it on the fly might be a valid attack vector, and it was. This year, they interpreted the HTML, extracted the Document Object Model, and trained some of the models on the DOM, stopping the older attacks.
In hacking AI phishing detectors, Biagio Montaruli finished 1st and Tobia Righi was 2nd. You can read more details about the phishing evasion results in the CUJO blog post.
AI Hacking Competition for Facial Recognition
The attack challenge against facial recognition was prepared by Adversa AI Red Team led by Eugene Neelou. The goal of the attacks was to modify people’s photos to be recognized as different identities while looking similar to the original images.
“We have designed this contest to raise awareness about vulnerabilities of AI algorithms”, says Eugene. Even though the challenge offers to bypass AI facial recognition, it’s only for the simplicity of visual demonstration. In fact, most types of AI systems are vulnerable by design and can be hacked in various unexpected ways, he adds.
The judging was based on metrics showing the similarity of an adversarial image to an original image and confidence indicating the probability of an adversarial image being classified as a victim class.
Attackers made millions of requests while probing AI systems for vulnerabilities. With so many attack attempts, we are yet to analyze the details of other AI attack strategies. However, one thing is clear: facial recognition cannot resist evasion attacks with adversarial examples.
Below we summarize the award-winning and the most effective attacks against AI models.
AI Hacking Competition 1st Place Award: Face Pasting Attack Upgraded with Adversarial Examples
The 1st place winner Alexander Meinke devised a strategy based on face pasting and blending original and victim photos. As Alexander detailed in his write-up, he started by pasting the part of the victim’s identity photo into the original identity photo. The AI system didn’t accept it at first but with extra optimization Alexander solved it.
While the AI attacks were successful, Alexander still competed against the others. He needed to optimize his metrics and spend hours to gain an extra 0.0005% for his total score.
Alexander wrote that he integrated an existing black-box method called Square Attack which is known to do well on some black-box attack tasks. This attack gets some budget for how much it is allowed to modify each pixel and then starts modifying square-shaped regions within this budget. Giving a large budget would reduce the stealthiness too much and giving a small budget would not improve the confidence but there was a sweet spot at which I obtained the following image. “Was the improvement of 0.0005% really worth spending several hours on this? Absolutely!”, Meinke adds.

Meinke finished 1st with a nearly perfect confidence score of 89.999912 out of 90 and a stealthiness score of 54.267957 and received a $3,000 prize.
AI Hacking Competition 2nd Place Award: A Mix of Adversarial Examples for Almost Perfect AI Attacks
The runner-up Zhe Zhao and his team not only took 2nd place but also made it with the 2nd least number of requests.
Unlike the winner, they started with adversarial examples right away. Zhao writes, “Essentially, the competition is a black-box adversarial attack on the face recognition neural network. So the main algorithm we use is based on model ensemble BIM or PGD attack. On this baseline algorithm, we have made several optimizations to this attack.”
Zhao’s team provides a detailed write-up on how they started with basic adversarial examples and added several attack optimization layers.
They ended up with quite advanced optimization for transferable adversarial examples. This transfer attack enabled local attack development with their local surrogate model. This is a remarkable strategy to attack AI systems because it’s harder to detect.
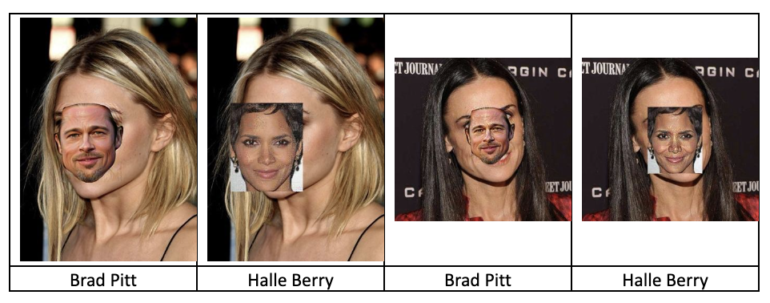
Zhao finished the 2nd with the second-best confidence score of 89.999494 out of 90 and stealthiness score of 48.719501 and received a $1,500 prize.
AI Hacking Competition Hardcore Award: Most Advanced Strategy for Adversarial Example Attacks
The most unique combo of adversarial techniques was introduced by Jérôme Rony. He was also the only participant who didn’t try to combine two images in one. Jérôme’s algorithm included methods spanning several papers of his cutting-edge research in adversarial machine learning.
The strategy was based on using a local surrogate model to create a reliable AI attack that is transferable to the black-box competition model. “The thing that made the transfer work well was that, at each iteration of the attack on the surrogate model, I was sampling a bunch of patches and averaging the confidence constraint on that. That way, whatever the patch in the image that was extracted by the detector, it would be adversarial”, Jérôme clarified.

With only a few hundred requests Jérôme got a score of 89.984533 out of 90 and the highest stealthiness score 61.053852 among all competitors. Later he tried to maximize the main metric but realized that further optimization is not feasible without attack algorithm redesign, which left him with the 4th place and an honorable mention by Adversa AI Red Team.
AI Hacking Competition Science Award: Street Smart AI Fooling Face Pasting Attack
Although scientists Niklas Bunzel and Lukas Graner didn’t rely on adversarial examples, they have designed one of the most resource-efficient algorithms as documented in their paper.
In their strategy, they pasted a face of a target into a source image. By utilizing position, scaling, rotation and transparency attributes with manual and automated masking, the approach took approximately 200 requests per attack for the final highest score and about ∼7.7 requests minimum for a successful attack.

By selecting the best results of both approaches, they got 89.998329 confidence and 57.685751 stealthiness scores, taking 3rd place.
AI Hacking Competition Creativity Award: Adversarial Face Swap Against Facial Recognition
Unlike other hackers, Ryan Reeves took advantage of our contest to unleash his creativity. Before the contest, he has been working on his face swap algorithm. Ryan tried to use his method but it wasn’t effective due to the adversarial hardening of our model.
Then, Ryan found a better algorithm called SimSwap. He has scraped Google images for hundreds of celebrity headshots and iterated over them selecting the photos with the highest confidence score. Then, he optimized confidence by blending original images with face-swapped ones. Surprisingly, he managed to improve stealthiness by brute forcing image dimensions that would “wildly swing the confidence score sometimes increasing it to 0.99 or greater from an original score of .50 or so”.

With this creative approach, Ryan collected 89.029803 confidence and 52.793099 stealthiness scores, finishing the 6th.
AI Hacking Competition Takeaways
It was very insightful to prepare, run and judge this competition and see dozens of efficient AI attacks.
As the final metrics demonstrate, the most efficient strategies involved Adversarial Attacks on Facial Recognition AI Algorithms, which had the best overall results (A combination of Stealthiness and Efficency) compared to more common deepfakes and presentation attacks and couldn’t be easily detected and mitigated. Moreover, Rony’s adversarial examples showed the best stealthiness which is one of the key characteristics of successful attacks in the real world.
This competition has demonstrated that AI algorithms are vulnerable by design, says Eugene Neelou. Many tech companies are becoming AI companies, and they rely on third-party or open-source models and datasets. Often they don’t audit or even can’t harden those neural networks. This jeopardizes AI product security and user safety for such companies”, admits Eugene Neelou, CTO and Co-Founder at Adversa AI.
To address AI security risks, companies need to rethink secure model development workflows.
First, they should raise security awareness across AI product & security teams about common AI cyber threats, vulnerabilities in relevant AI applications, and the severity of consequences.
Next, they should conduct adversarial testing and AI red teaming for understanding the true security level of their AI models before releasing AI-enabled products. As hackers demonstrated, there are many ways to perform successful AI attacks. Thus, companies should pay special attention and hire domain experts to address security AI risks. This includes the Validation of AI algorithms against adversarial attacks as highlighted by the White House’s AI Bill Of Rights and seconded by Gartner and CBInsight as top technology trends for 2023 and beyond.
Finally, they should implement a secure AI lifecycle from secure data engineering and processing to secure model development and hardening to threat detection and response.
The best and only way to protect models is to use a combination of controls at different stages of a pipeline. There are various defense techniques during training and inference such as adversarial retraining, input modification, attack detection, and other methods. The earlier the stage the stronger protection is possible. That’s why it’s better to shift left security controls.
BOOK A DEMO NOW!
Book a demo of our LLM Red Teaming platform and discuss your unique challenges



