The Adversa team makes for you a weekly selection of the best research in the field of artificial intelligence security
It has been proven that deep neural networks (DNNs) are vulnerable to malicious patches that make changes that are invisible to the human eye but affect the operation of the system. As a rule, such patches are applied to images, while it is an order of magnitude more difficult to apply them to video files, and this issue has been studied to a lesser extent at the moment.
In this regard, researchers Kai Chen, Zhipeng Wei, Jingjing Chen, Zuxuan Wu, and Yu-Gang Jiang have introduced a new adversarial attack – the bullet-screen comment (BSC) attack, which attacks video recognition models using BSC.
Adversarial BSCs are generated using a reinforcement learning framework with the environment as a target model, where the agent plays the role of positioning and transparency of each BSC. By regularly polling target models and receiving feedback, the agent makes adjustments in the selection strategies in order to achieve a high rate of deception with non-overlapping BSCs. Since BSC In addition, adding this patch to a clean video will not affect people’s understanding of the video content and will not look suspicious. Multiple tests have confirmed the effectiveness of the method.
In this paper, researchers Kai Chen, Zhipeng Wei, Jingjing Chen, Zuxuan Wu, and Yu-Gang Jiang propose a new hostless Trojan attack with triggers. They are captured in semantic space, but not necessarily in pixel space. Typically Trojan attacks use raw input images as hosts to transmit small meaningless trigger patterns. However, this attack treats triggers as full-size images belonging to a semantically significant class of objects. In the presented attack, the backdoor classifier is encouraged to memorize the abstract semantics of trigger images, so that it can later be triggered by semantically similar but different-looking images. Thus, the attack becomes more practical for use in the real world. Experiments have shown that the attack requires a small number of Trojan patterns to learn to generalize to new patterns of the same class of Trojans and can bypass the most modern defense methods.
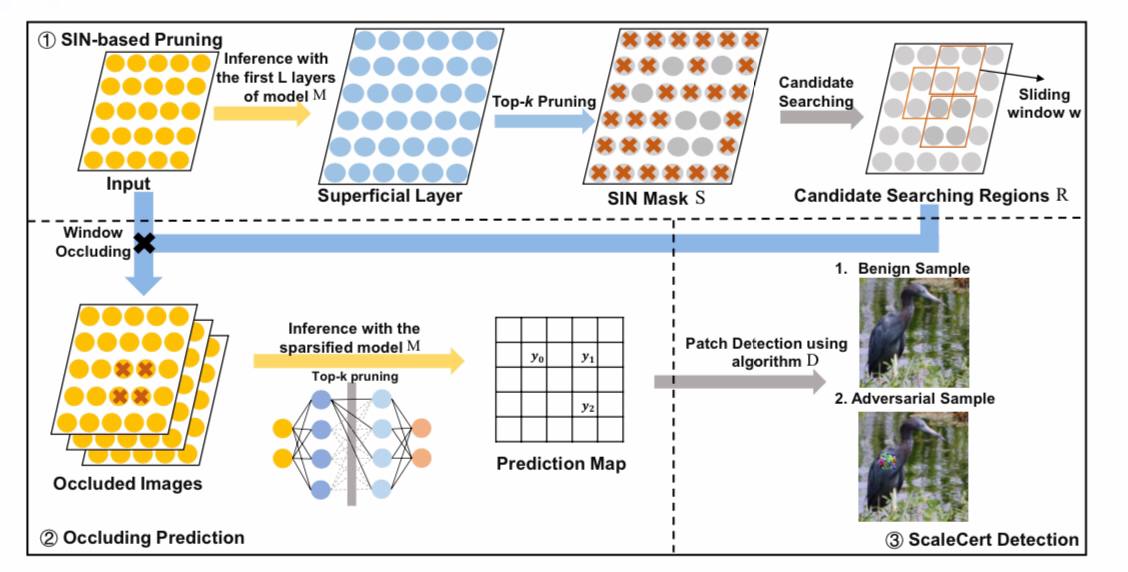
Adversarial patch attacks that create pixels in a specific area of input images are effective in physical environments, even with noise or warping. Existing certified protections against such patches work well with small images such as the MNIST and CIFAR-10 datasets, but their certified accuracy is very low on higher resolution images. There is a need to develop a reliable and effective defense against such a practical and malicious attack on industrial-grade large images.
In this paper, Husheng Han, Kaidi Xu, Xing Hu, Xiaobing Chen, Ling Liang, Zidong Du, Qi Guo, Yanzhi Wang, and Yunji Chen present a certified security methodology that provides high demonstrable reliability for high-resolution images and greatly enhances the ability to implement certified security. A hostile patch intends to use localized surface critical neurons (SINs) to manipulate prediction results, so SIN-based DNN compression techniques are used to significantly improve certified accuracy by reducing the overhead of confrontation search and filtering out predicted noise.