The Adversa team makes for you a weekly selection of the best research in the field of artificial intelligence security
Deep neural networks are deeply vulnerable to adversarial examples, and this has led to a huge amount of research to strengthen models and increase their resistance to attacks.
However, many of the existing security evasion techniques are easily mitigated by a variety of attack components. Therefore, researchers Yuejun Guo, Qiang Hu, Maxime Cordy, Michail Papadakis, and Yves Le Traon presented MUTEN, an inexpensive method to increase the success rate of well-known attacks on gradient cloaking models. The method is based on the idea of applying attacks to an ensemble model built by changing the initial elements of the model after training. The mutant diversity turned out to be a key factor in increasing the probability of success, so the researchers have developed a greedy algorithm to efficiently create a variety of mutants. As part of the work, the experiments were held on MNIST, SVHN, and CIFAR10 and demonstrated that MUTEN could increase the success rate of four attacks by up to 0.45.
In the given work, the researchers including Ting Chen, Saurabh Saxena, Lala Li, David J. Fleet, and Geoffrey Hinton demonstrate Pix2Seq, which is a new simple framework for object detection.
While most of the existing approaches rely on previous knowledge of the problem, in the new approach, object detection becomes a language modeling problem due to the observed input pixels. Object descriptions are in the format of a sequence of discrete tokens, thus a neural network. learns to perceive the image and generate the desired sequence. The new approach is distinguished by its intuitiveness, meaning that if the neural network knows where and what objects are, we just need to teach it to read them. In addition to using data augmentation for specific tasks, the framework makes minimal assumptions about the task, allowing for competitive results on the complex COCO dataset versus highly specialized and well-optimized detection algorithms.
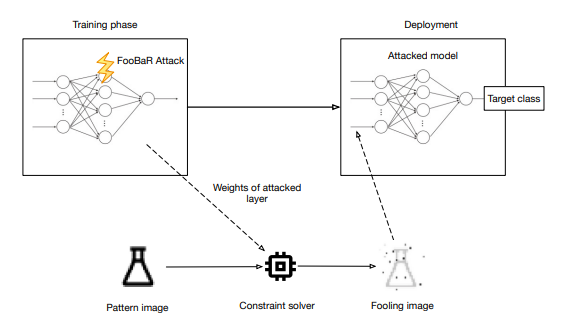
The current problem of neural network implementations is that they are highly vulnerable to physical attack vectors, for example fault injection attacks, which are normally implemented during the inference phase in order to cause a misclassification.
In the new study, the specialists Jakub Breier, Xiaolu Hou, Martín Ochoa, and Jesus Solano consider a new attack paradigm in which errors are introduced at the stage of training a neural network so that the resulting network can be attacked during deployment without the need for further faulting. Researchers are discussing attacks on ReLU activation functions, which are used to generate a group of malicious inputs called spoofed inputs. They will be used during inference to trick the model and cause controlled misclassifications. Such malicious inputs are obtained by mathematically solving a system of linear equations, and they can cause certain behavior of the attacked activation function. Researchers call these attacks fooling backdoor because failing attacks in the learning phase inject backdoors into the network that allow an attacker to produce spoofing inputs. After multiple evaluations, the method received high rates of attack success.